MLConf Seattle
10 May 2015
A couple of weeks ago I attended Seattle’s first MLConf, a one-day machine learning conference. I knew from YouTube videos just how good this was going to be, and I wasn’t disappointed.
Here are some highlights:
Network Effects
Folksy Wisdom: Wear an interesting t-shirt. It’s an instant conversation starter, and you’ll make some good contacts. I met data scientists, a researcher, and a presenter this way.
The machine learning / data science community is small. Most people who talk about ML don’t do any; they’re vendors, executives, sales folks, and the press. The core group of practitioners is pretty tight-knit, even in tech-savvy Seattle.
One of the best ways to learn is from the smartest people you can find. If you become only halfway close to their level of competence, you’ll be more clever than your competition.
Money Effects
Like many small conferences, MLConf was heavily vendor-supported. The result was the usual bevy of startups trying to compete with Amazon by impressing everyone with their sales pitches “presentations”.
That’s fine, I suppose. I don’t mind sitting in the audience while these folks speak; it’s a good time to catch up on reading research papers.
| Geeky Wisdom: P(sales pitch | presenter has C-suite job) = .99999 |
Speed and Consistency
Machine learning, more than many disciplines, moves incredibly quickly from academic paper -> open-source library -> competitive advantage. This is a career where your skills become obsolete faster than in software engineering.
The key challenges in ML are timeless:
- Defining the right objective function (target metric) for the business goal.
- Identifying which algorithms are the best choices for a problem.
- Feature extraction.
Work that Matters
Some folks are working to make a difference. One example is medicine, where machine learning is used to do real-time fMRI decoding, genomic sequencing for personalized medicine, image classification of x-rays, and more. If you’re tired of working on online ads and want to help the world, this is a good option.
The challenges are substantial. Most medical data faces the curse of dimensionality. There are more features than patients, or even humans. Our physiology interacts in complicated and subtle ways, so data measurements are constantly skewed and biased.
As a result, many techniques must be invented just for medicine, proven, and then re-written to scale.
Concepts to Learn
Tensors
Tensors are an intriguing, but complicated, concept. My basic understanding is that unlike 1d arrays or 2d matrices, tensors are higher-dimensional structures. Anima Anandkumar, a professor from UC Irvine, spoke about some of the opportunities. Her talk gave a brief overview of some of the opportunities and challenges:
- Tensor methods can lead to better neural network accuracy when used instead of backpropagation.
- Tensor methods lead to interesting approaches to spectral (dimensional) decomposition. Imagine a tensor with a million-by-million features - it can be reduced to a lower-dimensional representation.
- The math involved in the theory is much more involved than matrix math; sometimes it’s NP-hard.
- However, some tensor decomposition algos are embarrassingly parallel for cloud-based systems (Spark), GPU systems
Amina’s hardly alone; influential people are talking about tensors. This’ll be an area to keep an eye on.
Deep Neural Networks
There’s a huge amount of media coverage of deep learning. Its results in the ImageNet competition and ability to self-identify features are truly impressive. However, it’s not a panacea…yet. The field is so new that there are few people proficient in their use, so practically nobody knows how to build, tweak, and support them. Plus, they’re effectively impossible to debug.
Deep learning is one of the few areas where revolutionary improvements in ML can come from, so it’s worth learning about.
However, it’s also an existential threat to feature engineering. If you remove feature engineering, and model selection, what you’re left with is…defining a business metric. You don’t need data scientists for that.
Learning at Scale
‘Big data’ has come to mean “build a distributed stack that can query X terabytes of data”. Learning at scale is a much more difficult challenge. Microsoft’s Misha Bilenko spoke about some of the approaches used by Azure’s ML systems, notably the Learning from Counts approach. It was great to realize that this idea isn’t new (it was previously used for ‘pattern tables’ when applied to CPU branch prediction).
One core lesson from the day was that clever engineering, good judgment, and heuristics are needed to advance the field of machine learning. Using just math, or just more hardware, doesn’t advance the state of the art.
Happy researching!
PermalinkPASS Summit - Topics, Topics Everywhere
05 March 2015
Background
Technical conferences live and die by their community, and their content. A community conference like PASS Summit succeeds when it helps its presenters.
Several weeks ago, PASS advertised a survey, asking the community what topics and sessions they would be interested in. The survey link was sent out with the PASS Connector to 122.5K subscribers, and there were 85 responses. That’s roughly typical for large email surveys.
Survey results and analysis
The raw survey results are available. However, one limitation with survey responses is sampling bias: survey results don’t reflect the audience they represent because some types of people respond more than others.
For example, 10.4 % of PASS Summit 2014 attendees were consultants, and yet only 3.6% of the survey responses were. To compensate for this, I biased (weighted) the survey results to be representative of the distribution of Summit attendees. In this example, consultant responses would be weighted by 2.88 (10.4% / 3.6% = 2.88).
The weighted survey responses are on GitHub.
Overview
Session Content
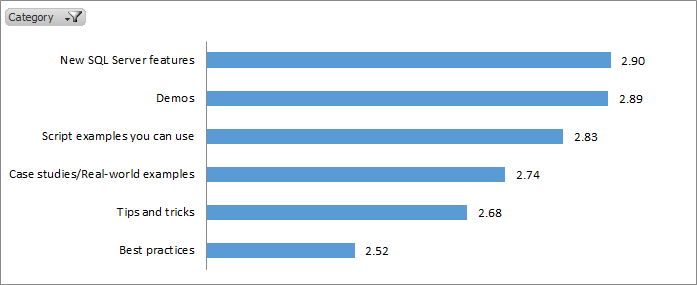
On a scale of 1-4 (4 meaning ideal interest), the most popular session content is for new SQL Server features, demos, and script examples.
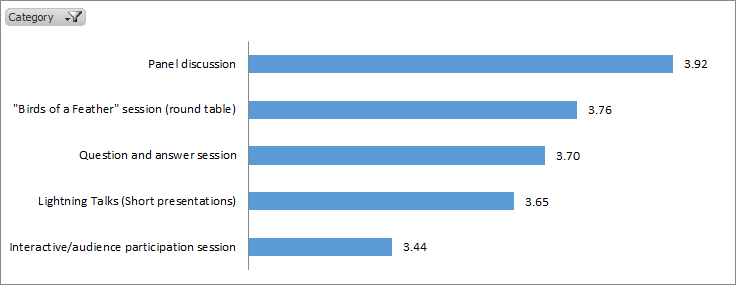
Session Format
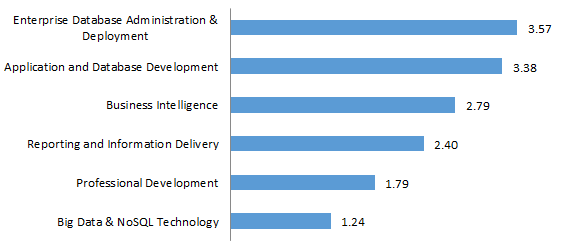
Tracks
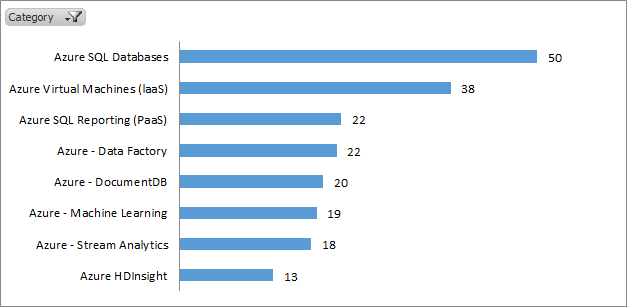
Topics of Interest
Azure
Application Development
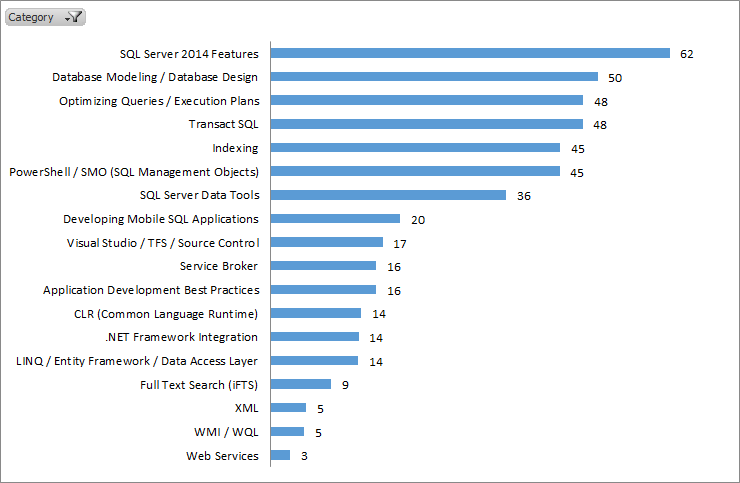
BI Information Delivery
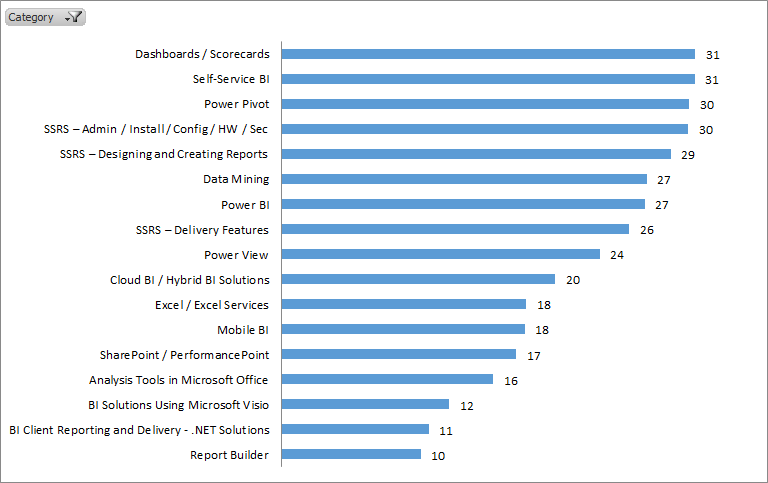
BI Platform Architecture
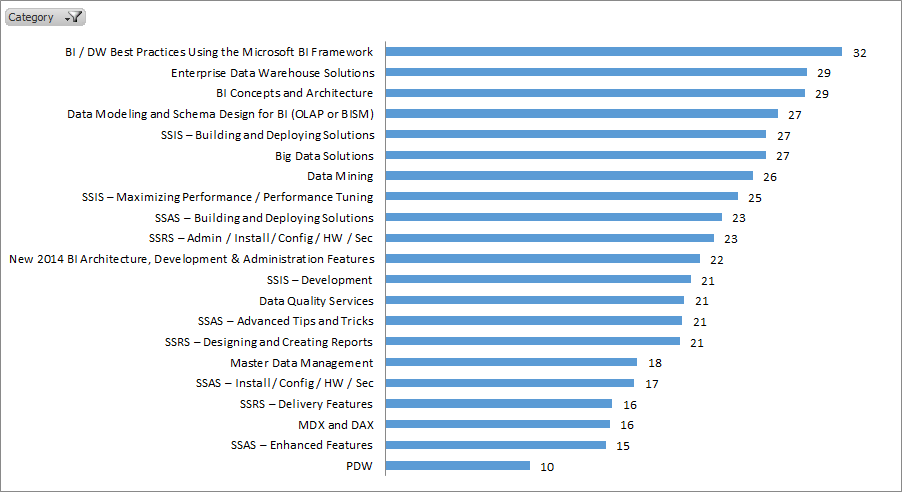
DBA
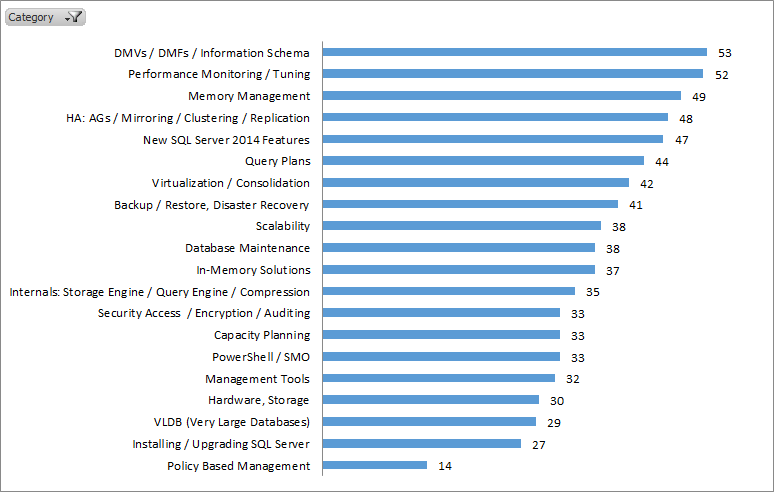
Professional Development
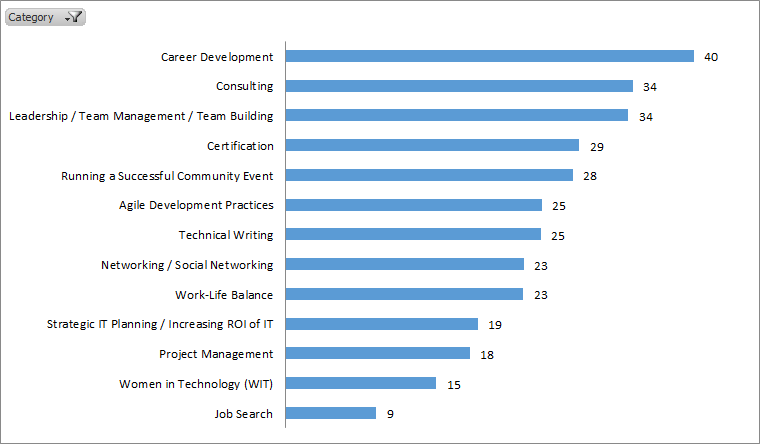
Interpretation
Looking at the data, I find a few interesting narratives:
- PASS Summit is a mature conference, and many people are return attendees. As a result, many of the best practices, tips-and-tricks styles of sessions have been done before.
- There is strong interest in panel discussions and ‘birds of a feather’ style events. I am guessing that’s because there’s not enough time to hear from all of the interesting people at PASS.
- DBA topics haven’t changed much since my SQL Server 2005 days: DMVs, performance tuning, monitoring, memory management, HA/DR.
- BI attendees are really interested in the latest stuff: PowerPivot, self-service BI, Azure BI, and Data Mining.
There are many, many different lessons and conclusions you can draw from this data, so I’ll let you speculate about the rest. Enjoy!
Permalink