Observations on Software Engineering
01 January 2013
Software engineering is a very human craft, full of trade-offs. These trade-offs don’t behave in a linear way. The reaction of “if __ is good, do more of it” _is therefore dangerously misguided.
Let’s see this visually:
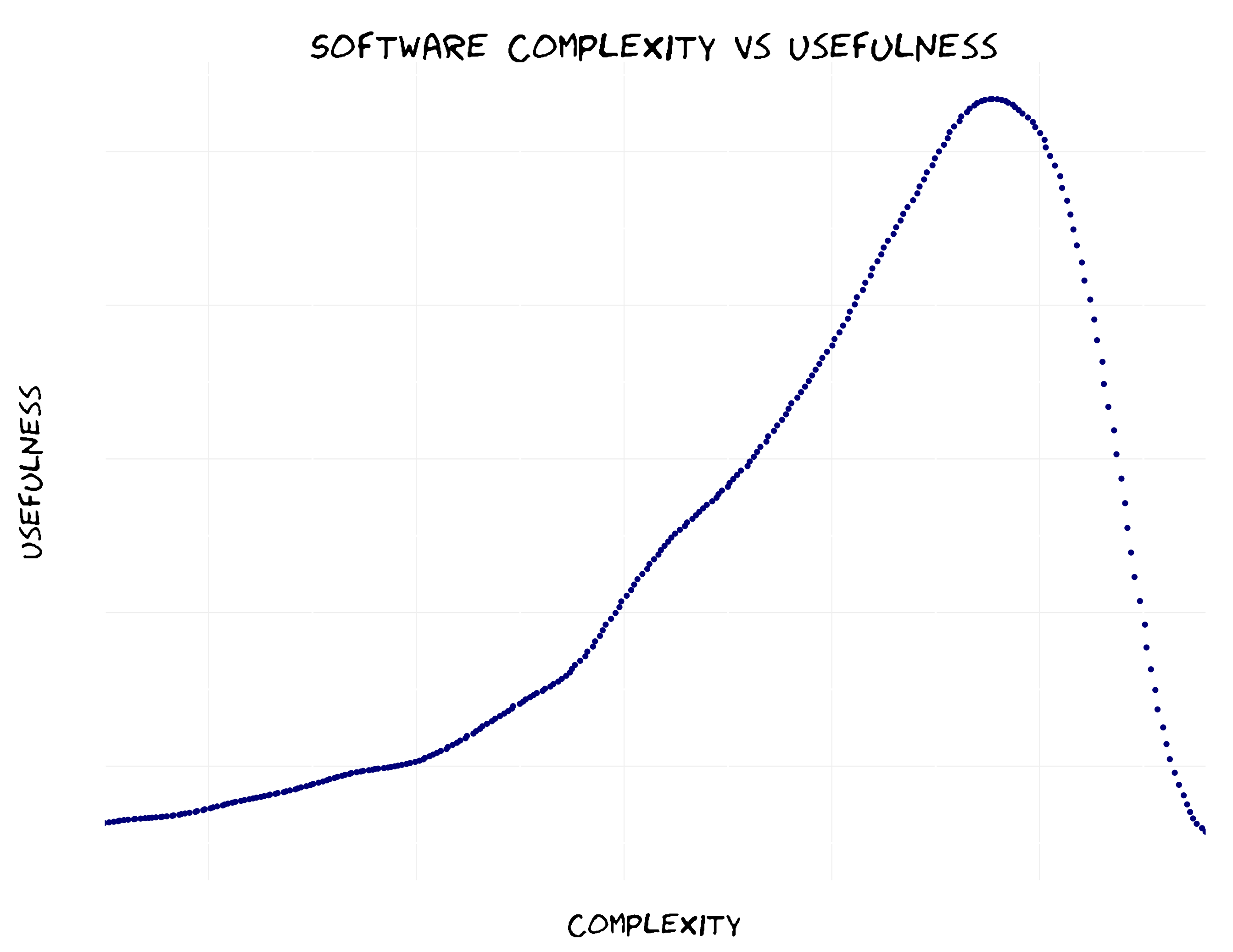
Software becomes more useful as features are added. However, software becomes useless as it becomes too complicated for its users.
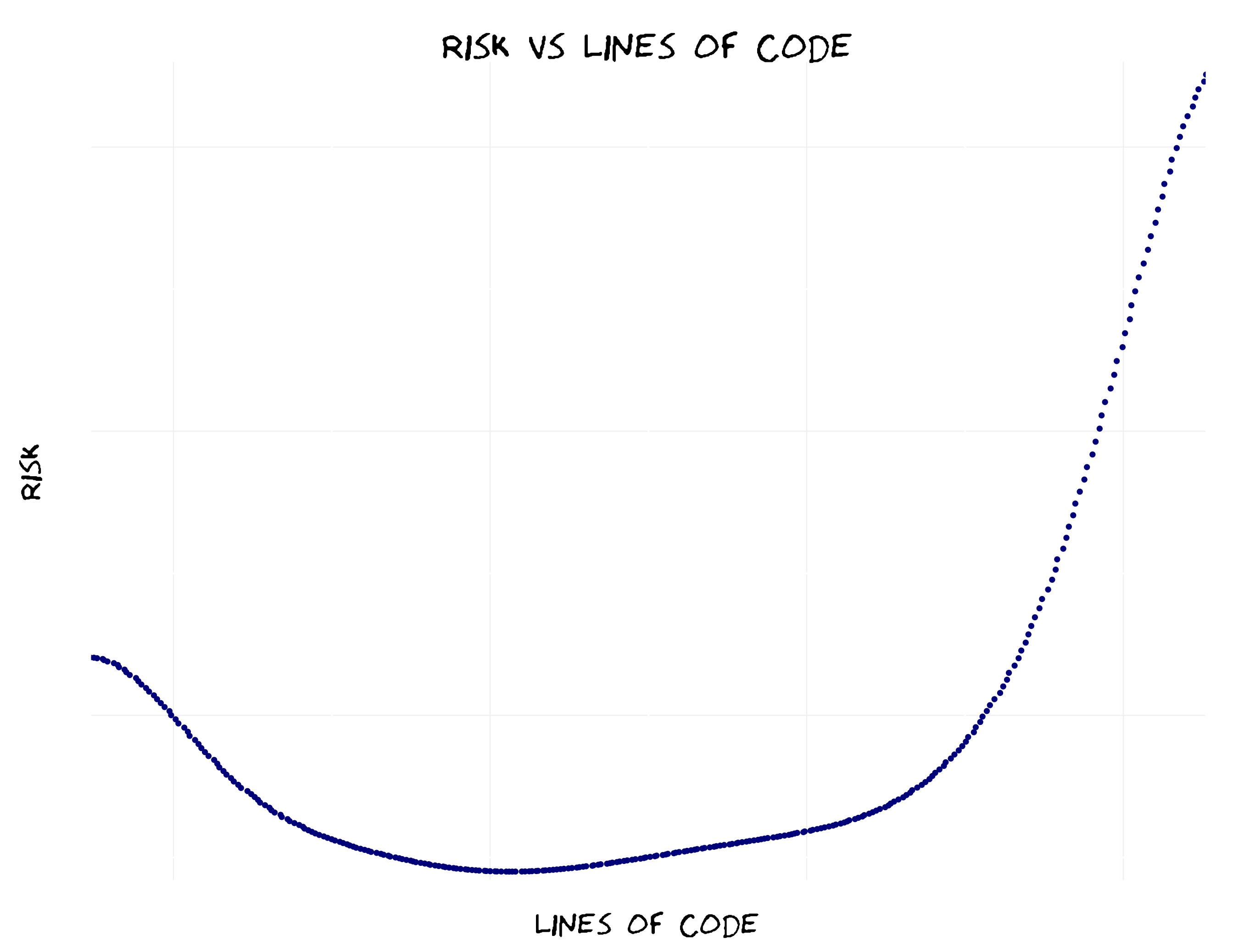
When an application has a small codebase, it is hard to change because it is highly coupled. When an application has a large codebase, it is hard to change because nobody understands the whole system.
The ideal balance is in the middle. Remember, all code is debt.

A common reaction to the trade-off above is to use existing components and tools instead of building your own. However, the time and cost of system integration between components spirals out of control as their number increases.
The Silicon Triangle
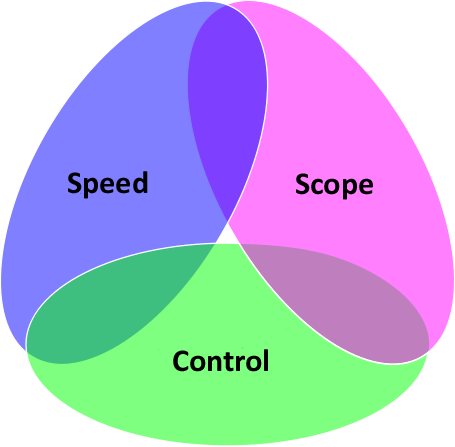
Pick two. Pick any two.
People want speed, scope, and total control. However, increased scope and control each requires more time. This is a classic trilemma. I call this variation of the Iron Triangle the Silicon Triangle.
Assets and Liabilities
| Asset | Liability |
|---|---|
| Commonly used features | Rarely used features |
| Normal users | Edge-case users |
| System uptime | System complexity |
| System scalability | System bottlenecks |
| Automation | Manual processes |
| Simplicity | Complexity |
| Test coverage | Lines of code |
| Domain expertise | Ignorance and hubris |
Where Do We Go From Here?
These compromises will affect everything you do. Find your own balance and wisdom. Reflect on your failures and successes. Use that insight to be wiser and thus more effective.
Happy New Year!
Note: these graphs don’t use real data; they are for illustration purposes.
PermalinkHardware and Architecture
13 November 2012
Software engineers and data professionals are constrained by the direction of computing hardware (Norvig). CPU speed has improved more quickly than the speed of RAM, and dramatically outpaced disk/network speed.
The Basics
- CPU / GPU capacity is increasing
- Memory speed isn’t really keeping up, but it’s doing alright
- Storage and networking are barely getting faster
An application can execute 8 million CPU instructions in the time it takes to do a 1 seek to disk. It can execute 150 million instructions in the time a packet does a network round trip via the Internet.
If your application goes to disk or the network, its performance capability slows down by several orders of magnitude. If the application has to do this synchronously, its performance is pretty well shot.
Let’s bring these speeds to human scale.
- A single CPU instruction takes about 1/2 a second.
- An L2 cache reference takes 7 seconds.
- Reading from RAM takes 100 seconds.
- Getting data from disk takes almost 17 weeks.
- Reading 1MB from disk takes ~8 months.
Implications
The abundance of computing speed and the relative scarcity of hardware/network speed has big implications for application design.
Algorithms and data structures that save disk/network usage at the expense of CPU cost are making an excellent trade. A canonical example is using compression to fit more of an application in into L1 cache, L2 cache, and RAM.
The most compelling features of some large data applications use compression:
- SQL Server columnstore indexes, xVelocity - data is compressed in a way to achieve high CPU cache usage.
- SQL Server Hekaton - keep everything in memory, no disk access needed.
- Google’s Dremel/BigQuery - data is stored in a columnar format and highly compressed.
- Caching applications/tiers use RAM instead of disk because the performance is two orders of magnitude (80-100X) faster.
- Hadoop clusters regularly compress their files for better performance.

It is cheaper to move code to the data than the reverse. A Hadoop cluster will try and sends the map() and reduce() code to the nodes that already have the data, for just this reason.
Web applications transmit compressed data to the browser, which can use JavaScript and abundant CPU power to do complicated rendering. This exploits two hardware trends:
- Compressed data is smaller than a corresponding graphic, reducing network delay. . There is more CPU capacity on 1,000,000 clients than 200 servers, so companies can buy less hardware for the same user load.
Big Fat Checks
The logic is different for enterprises. Proven, reliable options are more important than fast or cheap ones. Large businesses are willing to spend more to buy tiered SAN storage than help their engineers learn about caching. Why? Because the former is vendor-supported and proven to work over decades.
This is a losing strategy. The best applications use hardware trends to their advantage, rather than try to overcome them using sheer scale or price.
The cost of basic compute resources (quad-core CPUs, 16-64GB of RAM, 2-3TB of magnetic disk) is dirt cheap and getting cheaper. Hardware and core applications are rapidly becoming a commodity or service.
Challenge = Opportunity
These ideas aren’t grasped by many engineers, and certainly not many architects. That’s a shame, but it means that it’s very possible to achieve dramatic performance improvements by thinking carefully.
For any hard-core engineers out there, I have a humble request: study compression algorithms. Write them into existing, easy-to-use libraries in as many languages as you can. In the long run, this has the potential to reduce cost and increase performance across a massive number of applications.
The 2010-2020 decade in computing is turning out to be an exciting one. Let’s help shape it to to be even better.
Permalink