Wikidly Taming the TMI Beast
12 July 2019
What’s your favorite way to pack for a weekend trip? What has experience taught you about how to build AWS Lambda layers? What’s the name of that you wanted to get at IKEA?

It’s impossible for me to remember everything; there’s just too much information (TMI!). Rather than resort to a drunkard’s search, I want to organize my information, and make it optimally useful at minimal cost.
The Memory Palace
One of my primary organizing tools is a personal knowledgebase, a form of external memory.
Since it’s a way for me to organize huge amounts of information, I think of it as a memory palace.
Kubernetes
Let’s look at an example. I was recently building a Kubernetes replicaset, and had to remember details about network overlays, Vault secrets, and health checks. There were two ways for me to do this:
- Remember it, by using memory techniques
- Access it quickly, either via search, or by other methods of information retrieval.
I knew about the incredible effectiveness of checklists, so you can guess which option I went with…
Requirements
Knowledge bases have a few traits:
- Most of the information is static or infrequently changing.
- There’s a large variety of content, including text, videos, tables, graphics, and audio.
- There are lots of references to public information: news websites, software documentation, and YouTube videos.
It was pretty clear that I needed a wiki, a common kind of transactive memory. There are other options…sort of.

I had some feature requirements for a wiki:
- Highly secure. I’ll be putting personal information on here, snippets of work code, even notes on my relationships.
- A design, build, and deploy time of less than 3 days.
- A simple design.
In addition, I had some technical requirements:
- All data is stored in files, and only in files. No backend database required
- Support for Markdown formatting
- Can run on OS X
- Free and open source.
After taking a look at dozens of different options, I had a shortlist: MDwiki and Wiki.js. Of these two, only MDwiki had all the features I wanted.

Unleash the Dev
Thankfully the installation and setup for MDwiki is very, very simple. I was able to get a basic setup working in about an hour.
I’ve published my installation instructions and basic on GitHub. There are also a suite of Layout and Gimmicks features I haven’t experimented with yet.

Success!
The results were everything I could hope for…
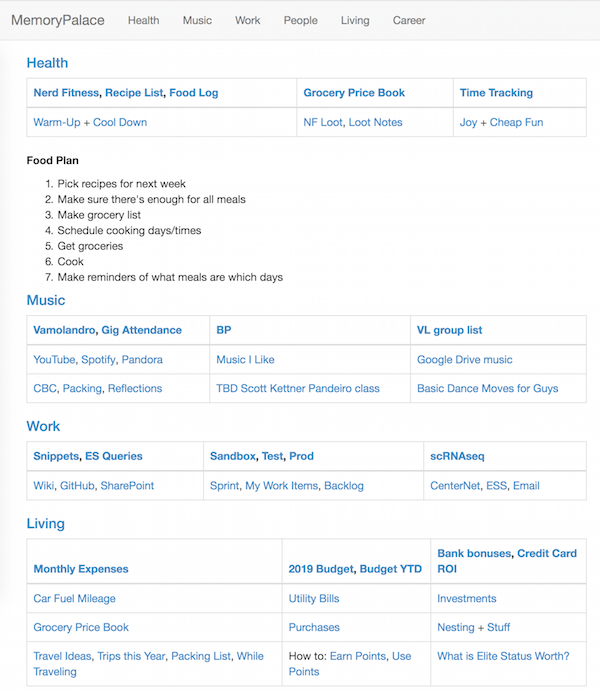
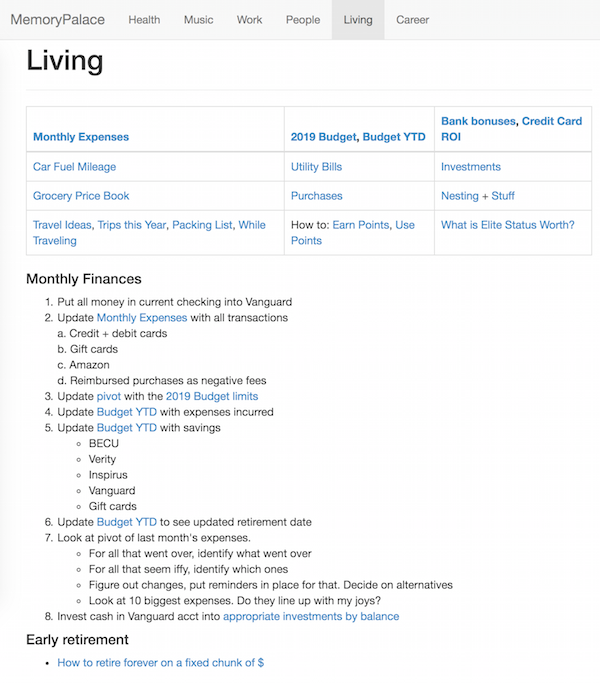
A few features stand out:
- Simple design. My data is stored in Markdown files, and Dropbox syncs everything.
- Low power usage. The only service running is Nginx, which is famously efficient.
- Secure by default. None of the data being served leaves my computer, except via Dropbox sync. When I browse to my site, I am connecting to
localhost:1138 - Easy to browse. I put in only the structure I need.
- Easy to change. All I need to do is edit a Markdown file. Doesn’t get much simpler than that.
4 of the goals in my previous post, were relevant to this work:
- Ability - Enable me to do what I want to do at any time, with the minimum amount of structure or interruptions.
- Search - Enable me to find all the information I need, and only the information I need, in less than 10 seconds
- Additions - Be able to add new information or structures in less than 30 seconds
- Privacy - Serve only me. I want minimal risk that this information will be used against me in the future.
The only goal not natively supported is Search. Though I can still search the wiki contents using Spotlight.
I have one outstanding security bug, because browser CORS restrictions don’t work for localhost.
This tool does exactly what I want it to.
In future posts I’ll go over yet more tools, habits, and topics to scaffold my intellect. Stay tuned!
PermalinkTaming the TMI Beast
07 July 2019
“AAAAAAA, THERE IS TOO MUCH INFORMATION!” - me, every day
The world has ever-increasing amounts of information. It’s a monster, useful if trained, and detrimental otherwise.
What I do depends on what I know at the time. For example, here are my info-centric questions from last week:
- What input/output structures are optimal for scrnaseq workflows spanning multiple labs?
- What do I cook next week, factoring in my health, food costs, and personal tastes?
- What’s the most effective way to teach the 9 newcomers in the musical group I’m in?
- What should I do with my last job’s 401K, considering the fees are too high?
- Where should I take a friend to see music next week, factoring in cost, their musical preferences, and schedule constraints?
- How do I make sure I get my work done, prioritize my health, spend time with friends, play music, sleep enough, and leave time to be spontaneous? How do I do this in a low-stress way?
When in Doubt, Generalize

Last week’s questions generalize to a few topics: intelligence augmentation, information retrieval, external memory, and habit formation.
Along with higher-level topics, I can generalize my constraints:
- Money - I can’t afford a personal assistant, chef, or to quit my job.
- Time - Most of my hours are spoken for.
- Focus - I must optimize for my median brainpower, not my full capacity.
- Inertia - I can change quickly, easily, or a lot…pick two.
Goals
Knowing the problem and background, I want goals. What would a solution to TMI look like? Funny you should ask…
- Ability - Enable me to do what I want to do at any time, with the minimum amount of structure or interruptions.
- Search - Enable me to find all the information I need, and only the information I need, in less than 10 seconds
- Additions - Be able to add new information or structures in less than 30 seconds
- Routines - Enable me to adopt, reflect, and change processes/habits with minimal effort.
- Change - Be portable, so I can shift my information to other tool(s) with minimal effort
- Privacy - Serve only me. I want minimal risk that this information will be used against me in the future.
I want to organize my information, and make it optimally useful at minimal cost.*
In future posts I will go over the different tools, habits, and topics I worked through to build my current information scaffolding. Stay tuned!
* - Yes, I based my goal on Google’s mission statement.
Permalink