All About College
10 December 2013
I was recently asked by my youth group to provide resources for high school students considering college. Here’s what I came up with…
Why College?
People usually go to college for a combination of a few reasons:
- It’s expected of you (by your parents, family, friends, etc)
- You’ve heard it’s the only/guaranteed way to get a good job and career.
- It’s how you “become an adult”
- You love to learn
- You don’t know what you want to do, and colleges help you find out.
Colleges are Valuable

Colleges and universities have incredible value.
- You can choose between dozens, even hundreds, of topics and specialties.
- They are institutions intended to advance knowledge.
- They are a place for young adults to gain valuable life skills…sometimes.
- They concentrate smart, interested, and dedicated people together. This is both inspiring and (sometimes) incredibly productive.
Learning, research, exploration. That sounds awesome. It is.
Unfortunately, college comes with painful trade-offs.
Colleges are Expensive

College is expensive. Really expensive.
There’s no one reason for this. There are several:
- Federal and state funding for colleges has gone down over the past decade, so tuition went up to make up the shortfall.
- Colleges are in a race to be ‘prestigious’, so they built fancy dorms for billions of dollars, stadiums, and hired like crazy.
- College sports cost lots of money, more than they ever make.
- Colleges are full of highly-paid people who don’t teach (administrators, advisors, etc)
- For-profit colleges take money from students and give it to shareholders. And they get away with it.
- Colleges are so deep in debt that many of them will probably be bankrupt in the next 15 years.
- There are entire industries that make money off of college students. They don’t want anything to change.
Which One?
Picking a College is Hard. You’re 17 or 18 and making choices that will affect your future for decades.
There are 2 brilliant sources of data that look at the cost of college vs. the payoff: Payscale and Priceonomics.
There are lots of bad choices, and only a few good ones
- Lists that rank college value are on the rise
- The highway through college is more like a windy road
- Are bigger universities better?
- Elite universities are often cheaper, because they have better financial aid
- Your choice of university likely mirrors your financial status. That maintains social inequality
Public Universities
Private, Nonprofit Universities
Private, For-Profit Universities
STAY THE HELL AWAY!
- For profit colleges: can they give up their predatory ways?
- The biggest for-profit college you’ve never heard of
- Full Sail College, Exposed
- For-profit colleges prey on ambition
The Real Problem
- Income isn’t going up. It’s flat or going down.
- The real problem is income inequality. Jobs that pay well and make you not feel corrupt are pretty rare
- This is very true in the US
- This is true in Europe, too
- Internships
- There’s a huge emphasis on graduating lots of students so that well-paying jobs now will go down in price (because there is more labor supply). This is STEM
What are the Alternatives?
Well, the future of learning is all about choice.
Community College & then transfer
- Well, except they struggle to meet academic standards
- The Gates Foundation is trying to make community colleges ‘feed into’ universities
Massive Online Open Courses (MOOCs)
- MOOCS are reaching people who are already highly educated
- MOOCs don’t make money and most students don’t complete classes
- What is college for, anyway?
- Why we need online open courses
- As Universities rush to online courses, a veteran player looks back
- However, students say online courses enrich on-campus learning
- Online courses and cheating
Debt is Evil
Debt is one of the most subtly evil and destructive forces around. If you owe lots of money, you can end up in a painful cycle of always struggling to make payments and never getting free.
The average student graduates with $29,400 in debt. With normal interest rates, that is $225 a month for 20 years, for a total of $53,900.
Student debt is particularly nasty because it’s so hard to get rid of. You can’t get rid of it by declaring bankruptcy. Lenders can garnish your wages. And if anything happens to you, your parents and future spouse can end up with the debt.
It’s Worse Than You Think
The trap is guaranteed. The escape route isn’t
- The student debt deals in Congress perpetuate predatory practices
- Student loan debts are like medieval indentures (read: serfdom)
- We must hate our children
- Thanks for nothing, college
- The vanishing value of a diploma
For-profit colleges are particularly bad
Graduate Degrees Don’t Help
- Law students can’t find jobs
- Grad Students: The Few. The Proud. The Indebted
- Grad students’ stipends aren’t much
Financial Aid Is Going to the Wrong People
- The student aid program is breaking its promise to the poor
- State aid is increasingly awarded based on merit, and not need
- Colleges soak the poor and funnel aid to the rich
Lots of Debt, no guarantee of a good job
- College graduates blame colleges for their debt woes
- Student loans make some companies and governments lots of money
- Student debt crushes the future of young people
- Student debt is like a Debtcropper system for the young
- College loans rip off young people
- More facts on student debt
If You Want to Know More
College Metrics and Gaming the System
- There are multiple arms races in the college system
- Education isn’t like sports. There isn’t supposed to be one winner, and the game isn’t the point
- The US News Ranking actually hurts students
- There are a lot of ways to game the system
- Nice college. What will I make when I graduate?
Tests Measure the Wrong Thing
- America’s Toxic Culture of Testing
- The architect of school reform turned against it
- “My profession no longer exists” - A teacher’s resignation letter
Nobody Knows How to Fix This
- Definitely not in my state
- The coming meltdown in college education
- A smart and utterly hopeless plan to make college cheaper
- A federal prod to lower college costs
- Open data and its effects on colleges
Picking a College and Admissions
- Rating college-planning sites
- White people are skeptical of the value of a college degree
- Colleges use FAFSA info to reject students
- Where should I go to college?
- Should you go to college?
- Measuring college prestige vs. price
- The poor and scholarly overlook better colleges they can get into
- Stay away from fraternities/sororities
What should you ‘really’ learn in college?
- Let’s kill off diplomas, transcripts and resumes
- Have degrees based on what you can do, not how long you went somewhere
- A free course in financial planning
- Offbeat Advice I wish I was given in college
- Programming
- The practical university
- If only I knew this shit in college
- My Fake College Syllabus
- A 15-year-old’s student reform plan
Epilogue
This blog post presents a biased view; it emphasizes the financial aspects of higher education (cost to attend, ROI of a degree) far more than their value to society, the intrinsic value of a college experience to a young adult, and so forth.
That’s the point. Students already hear enough about the importance of going to college that I want to provide a counterpoint.
In addition, I haven’t looked at higher education in other countries, vocational schools, service learning, or apprenticeships. There are many, many options available to young people, but they require research and curiosity to find.
I expect smart young students to face different perspectives and narratives, analyze the merits of each, and come to their own conclusions.
PermalinkPageRank in SQL
03 December 2013
One of the most profound ideas in the last 20 years is PageRank, the original algorithm of Google’s search engine.
PageRank starts with a simple and clever idea: the importance of a page is determined by how many pages link to it, and how important they are. It’s a link-analysis algorithm, and it ranks pages by how important they are to the entire collection.

In other words, when a source page (like this blog) links to another, target page (like a Wikipedia article), some of the source’s importance should transfer over to the target.
The only things you need are pages and their links. It’s a graph structure.
SQL and Graphs
A graph can be stored in SQL using 2 tables, Nodes and Edges
CREATE TABLE Nodes
(NodeId int not null
,NodeWeight decimal(10,5) not null
,NodeCount int not null default(0)
,HasConverged bit not null default(0)
,constraint NodesPK primary key clustered (NodeId)
)
CREATE TABLE Edges
(SourceNodeId int not null
,TargetNodeId int not null
,constraint EdgesPK primary key clustered (SourceNodeId, TargetNodeId)
,constraint EdgeChk check SourceNodeId <> TargetNodeId --ignore self references
)Imagine a node is an object like a web page. An edge is a pointer from a source node to a target node, like a hyperlink pointing from one web page to another.
We are preventing a few things. We ignore edges where a node points back to itself. And a node is allowed to point to another node only once.
Imagine a Tiny Web
Imagine the Internet has just 4 web pages: pages 1, 2, 3 and 4. These pages have links between them:
- Page 2 links to pages 1 and 3
- Page 3 links to page 1
- Page 4 links to pages 1, 2 and 3.
- Page 1 links to nothing.
We can store this in SQL
INSERT INTO Nodes (NodeId, NodeWeight)
VALUES
(1, 0.25)
,(2, 0.25)
,(3, 0.25)
,(4, 0.25)
INSERT INTO Edges (SourceNodeId, TargetNodeId)
VALUES
(2, 1) --page 2 links to pages 1 and 3
,(2, 3)
,(3, 1) --page 3 links to page 1
,(4, 1) -- page 4 links to the 3 other pages
,(4, 2)
,(4, 3)Initially, we give all nodes the same weight, 0.25. All nodes start out equal.
Get Ready!
We need to know how many edges each node has pointing away from it. Imagine counting the number of links a web page has going somewhere else. Let’s calculate that and store it in our Nodes table.
declare @TotalNodeCount int
set @TotalNodeCount = (select count(*) from Nodes)
UPDATE n
--if a node has 0 edges going away then assign it the total # of nodes.
SET n.NodeCount = isnull(x.TargetNodeCount, @TotalNodeCount)
FROM Nodes n
LEFT OUTER JOIN
(
SELECT SourceNodeID,
TargetNodeCount = count(*)
FROM Edges
GROUP BY SourceNodeId
) as x
ON x.SourceNodeID = n.NodeIdGet Set!
Let’s look at the most important part: calculating how we transfer weight from source nodes to targets.
- The weight of each target node is the sum of the nodes’ weights that point to it, sum(n.NodeWeight)
- Divide each source node’s weight by the number of nodes it links to, n.NodeCount
- Only transfer part of the weight, multiplying by the @DampingFactor, 0.85
SELECT
e.TargetNodeId
,TransferWeight = sum(n.NodeWeight / n.NodeCount) * @DampingFactor
FROM Nodes n
INNER JOIN Edges e
ON n.NodeId = e.SourceNodeId
GROUP BY e.TargetNodeIdYou can see there’s a damping factor, which is the percentage of a node’s weight that gets transferred via its edge to another node.
We also include a margin of error, which is a small number that represents an acceptable amount of precision.
Now we’re ready to run PageRank.
GO!
declare @DampingFactor decimal(3,2) = 0.85 --set the damping factor
,@MarginOfError decimal(10,5) = 0.001 --set the stable weight
,@TotalNodeCount int
,@IterationCount int = 1
-- we need to know the total number of nodes in the system
set @TotalNodeCount = (select count(*) from Nodes)
-- iterate!
WHILE EXISTS
(
-- stop as soon as all nodes have converged
SELECT *
FROM dbo.Nodes
WHERE HasConverged = 0
)
BEGIN
UPDATE n SET
NodeWeight = 1.0 - @DampingFactor + isnull(x.TransferWeight, 0.0)
-- a node has converged when its existing weight is the same as the weight it would be given
-- (plus or minus the stable weight margin of error)
,HasConverged = case when abs(n.NodeWeight - (1.0 - @DampingFactor + isnull(x.TransferWeight, 0.0))) < @MarginOfError then 1 else 0 end
FROM Nodes n
LEFT OUTER JOIN
(
-- Here's the weight calculation in place
SELECT
e.TargetNodeId
,TransferWeight = sum(n.NodeWeight / n.NodeCount) * @DampingFactor
FROM Nodes n
INNER JOIN Edges e
ON n.NodeId = e.SourceNodeId
GROUP BY e.TargetNodeId
) as x
ON x.TargetNodeId = n.NodeId
-- for demonstration purposes, return the value of the nodes after each iteration
SELECT
@IterationCount as IterationCount
,*
FROM Nodes
set @IterationCount += 1
ENDVictory!
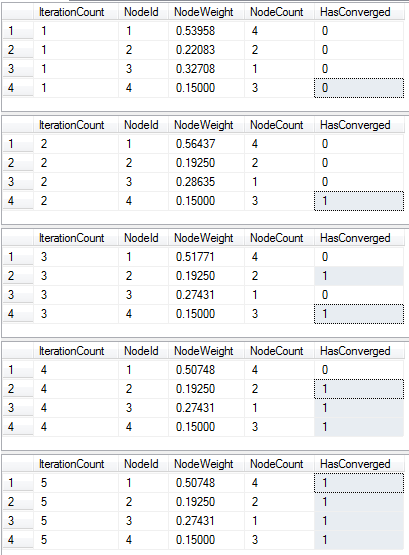
This example takes 5 iterations to complete. It turns out computing PageRank for the entire world wide web takes only 100 iterations.
I’d recommend you try this out yourself. My code is available on GitHub.
Happy Coding!
Permalink