ElasticSearch Snippets
28 December 2019
I do a bunch of work with ElasticSearch, building tools so researchers can search through large amounts of data. I’ve had to figure out a bunch of useful queries for searching, aggregations, deletes, and index management.
In this example, I will use an index, twitter, that has account, tweet, retweet_count, language, and country fields.
Each record/document is a tweet, and one of the accounts is for @devnambi
Searches
Search everything
GET twitter/_search
{
"query": {
"match_all": {}
}
}
Search for a single word
GET twitter/_search
{
"query": {
"bool": {
"must": [
{ "match": { "account": "devnambi" }}
]
}
}
}
Search for multiple words
GET twitter/_search
{
"query": {
"bool": {
"must": [
{ "match": { "tweet": "Hello World" }}
]
}
}
}
Search for multiple lower-case words
GET twitter/_search
{
"query": {
"bool": {
"must": [
{ "match": { "tweet": "hello world" }}
]
}
}
}
Records for a given dataset name (w/ tokens)
Single-word:
GET twitter/_search
{
"query": {
"bool": {
"must": [{
"term": {
"tweet": "example"
}
}
]
}
}
}
}
Multiple-word:
GET twitter/_search
{
"query": {
"bool": {
"must": [{
"term": {
"tweet": "include"
}
},
{
"term": {
"tweet": "all"
}
},
{
"term": {
"tweet": "these"
}
},
{
"term": {
"tweet": "words"
}
}
]
}
}
}
}
Aggregations
Count of records by country
GET twitter/_search
{
"size": 0,
"aggs" : {
"source" : {
"terms" : {
"field" : "country.keyword"
}
}
}
}
Count number of records for a filter
GET twitter/_search
{
"size" : 0,
"query": {
"bool": {
"must": [
{
"match": {
"country.keyword": "US"
}
}
]
}
},
"aggs" : {
"source" : {
"terms" : {
"field" : "country.keyword"
}
}
}
}
Sum of retweets for an account
GET twitter/_search
{
"size" : 0,
"query": {
"bool": {
"must": [
{
"match": {
"account.keyword": "devnambi"
}
}
]
}
},
"aggs" : {
"source" : {
"sum" : {
"field" : "retweet_count"
}
}
}
}
Get tweet count by account
GET twitter/_search
{
"size" : 0,
"aggs" : {
"source" : {
"terms" : {
"field" : "account.keyword"
}
}
}
}
Get average size of all tweets in the UK
GET twitter/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"country.keyword": "UK"
}
}
]
}
},
"aggs":{
"avg_length" : { "avg" : { "script" : "_source.tweet.toString().getBytes(\"UTF-8\").length"}}
}
}
Get unique count of tweets in Germany
GET twitter/_search
{
"size" : 0,
"query": {
"bool": {
"must": [
{
"match": {
"country.keyword": "DE"
}
}
]
}
},
"aggs" :
{
"unique_filecount": {
"cardinality" :
{
"field" : "tweet"
}
}
}
}
Get records with missing retweet_count field by country (no retweets)
GET twitter/_search
{
"size": 5,
"query": {
"bool": {
"must_not": [
{
"exists": {
"field": "retweet_count"
}
}
]
}
},
"aggs": {
"sources": {
"terms": {
"field": "country.keyword",
"size": 10
}
}
}
}
Get multiple aggregations
GET twitter/_search
{
"size" : 0,
"aggs" : {
"countries" : {
"terms" : {
"field" : "country.keyword"
}
},
"accounts" : {
"terms" : {
"field" : "account.keyword"
}
}
,"languages" : {
"terms" : {
"field" : "language.keyword"
}
}
}
}
Sources: % Increase, Term Percentage, Search Agg Pipeline
Deletes
Delete all tweets by account name
POST /twitter/_delete_by_query?conflicts=proceed
{
"query": {
"bool": {
"must": [{
"term": {
"account": "devnambi"
}
}
]
}
}
}
}
Index Management
Index name in examples: twitter
Alias name in examples: social_media
Get Indexes
GET /_cat/indices?v
Delete an index
DELETE /twitter
Change the index refresh interval
PUT /twitter/_settings
{
"index" : {
"refresh_interval" : "1s"
}
}
Aliases
Get aliases
GET /_cat/aliases?v
Set an alias
POST /_aliases
{
"actions" : [
{ "add" : { "index" : "twitter", "alias" : "social_media" } }
]
}
Remove an alias
POST /_aliases
{
"actions" : [
{ "remove" : { "index" : "twitter", "alias" : "social_media" } }
]
}
No piece of code is ever done. I can think of various improvements to improve query performance or add functionality. I’ll add those over time.
Happy coding!
PermalinkTaming the TMI Beast through To Do Lists
27 July 2019
What was that errand I had planned after work tomorrow? When’s my next dentist appointment? Which friend wanted to borrow my car this weekend?

I cannot remember everything I’m going to do today, let alone this week, or next month. There’s too much information (TMI!). Rather than rely on my memory or a huge collection of email, I want to organize my information, and make it optimally useful at minimal cost.
I’ve already talked about how I do this with my Memory Palace. The tool I use most, however, is a to-do list.
The Hourglass

There is never enough time
I have too many things to do. I’m sure this is unique to me. Surely no one else is busy, overworked, or juggling too many responsibilities. Right? Right.

Because I’m one of those weirdos with too much to do, I try to be prudent with my time.
That means:
- I want to do each task as efficiently as possible
- I want to get more things done in the same amount of time
- I want to do each task with less and less mental effort over time.
The Magic of Context
comic courtesy of Jason Heeris
People are terrible at multitasking. Therefore, one way to be very productive is to group together like-minded things together.
For example:
- Pay my rent on time. And my garbage bill. And my phone bill. And my credit card bill, while you’re at it.
- Cook food for the week. While I’m at it, make a vat of tea. And cut up fruit for snacks
- Get groceries after work. Oh, and don’t forget to get some WD-40, you’re running low. Oh, and pick up that tent from a friend.
- Do my workout in the morning, as soon as I wake up. Oh, and shave right after. Might as well trim my nails then, too.
When I group together like-minded tasks, I can do them with less effort overall. Tasks in the same context flow together.
The Elephant and the Mouse

One of the most useful books I’ve ever read is Thinking, Fast and Slow. It describes a person’s mind as a mouse riding an elephant.
The mouse (your conscious mind) is trying to direct the elephant (your habits & instincts). Most of the time the elephant goes where it wants. The mouse can steer very gradually (i.e. forming habits) or by sheer force (i.e. willpower). In the latter case, the mouse will quickly exhaust itself.
This describes my daily life perfectly. I have a limited supply of willpower (like everyone else), and must allocate it wisely. I have found 2 approaches that work well:
Proactively Form Habits
I’m very much a creature of habit, and that has served me well. For example, my big push this year is to focus on my health, and so I’ve been slowly making a habit of meal prepping, sleeping enough, taking breaks, cycling, working out, and rewarding myself for good behavior.
Baby Steps
The second approach is ‘baby steps’; I will break a task into tiny, trivially easy to do pieces. It’s then easy for me to breeze through them, because the mental effort involved in any single step is miniscule.

The Tool
I had a few requirements for a to-do list tool, based on how I organize tasks:
- Works on all of my devices (laptops, smartphone, desktop) and stays in sync
- Supports prioritizing tasks, at least a bit (high, medium, low)
- Has support for tasks with due-dates
- Supports recurring tasks
- Has enough organizing structure that I can easily segment my tasks by context
I’ve experimented with several different approaches over the years, including:
- Microsoft OneNote, synced with Dropbox
- Google Calendar
- Google Inbox
- Wunderlist
However, none of these had enough organizing structure, or the right design for a to-do list. It was only last year that I found a really good tool: Todoist.
I was initially skeptical, since I’d used Wunderlist, and it didn’t let me segment/cluster items enough. The breakthrough was reading about a Getting Things Done blog post by Vernon Johnson, describing his Todoist setup.
Todoist
Todoist is quite simple. You can create tasks. Each one can belong to a project, have tags, a due date, a priority, and can be recurring or not.
I set up my projects to be categories (e.g. music, work, travel, house, friends)
Grouping
The most natural grouping for me is by time:
- Morning tasks (before work)
- Midday tasks (during the work day)
- Afternoon tasks (right after work)
- Evening tasks (once I’m back in my house)
- Quick tasks (takes less than 10 minutes)
Tags are how I make this magic happen. I’ll tag a task with @morning, and I will see it when I roll out of bed and check my ‘Morning’ list.
Let’s say I want to work out three mornings a week. I can create three recurring tasks, one for each day of the week, and tag them with ‘morning’,
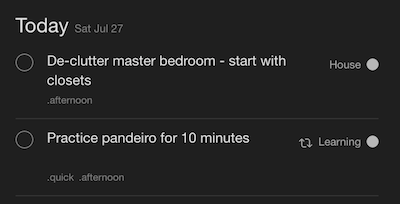
Here are my tasks this afternoon:
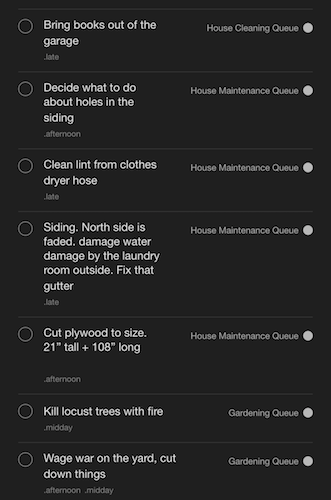
…and some of tomorrow’s tasks, organized by project:
But Beware…

It’s very, very, very tempting to use productivity tools to get more done. However, that’s a cycle without an end; you’ll end up doing more, instead of getting time back.
“When everything is important, nothing is”
To decide what to do, decide on what’s important. That means making conscious choices on what is not important. If you’re like me, it’s painful to decide that a whole category of things isn’t important (e.g. ‘house repairs’, or ‘travel’).
I cannot overstate how valuable it is, though. I decide on my priorities every month, and change what I do as a result.
I use a mnemonic when adding/changing tasks:
- Leave - Do I really need to do this? Is it really important to me? If not, can I get rid of it, or leave it for a later month?
- Link - For this task, what other tasks are similar? Does it make sense to link them together?
- Limit - How can I keep limit this task’s time/scope/effort? Can I break it into pieces?
The result? I can be really damn productive, and then I can stop and enjoy life.
