DB Perf Is Like Cake: The Physical Layer
24 March 2011
“Build It, and Perf Will Come”

Layer 1 of The Layer Model is the physical layer.
The physical layer is the hardware used to make your database run. If you add more/better hardware, you can get better performance. Just add a faster SAN array, more RAM, more CPU cores, etc. Hardware upgrades will improve your application’s performance. Of course, you need to know which hardware to add.
The best way to do this is to use the Waits and Queues method. It quickly identifies the bottlenecks in your system, so you can tune hardware in the places you need it most.

The main Waits and Queues whitepaper is here, written by Tom Davidson. In addition, I’ve found a few blog posts to be very helpful. Paul Randal (b / t) has a great post expanding on the different wait types, with some example queries to get you started. The other fantastic resource is Brent Ozar’s (b / t) series of blog posts on scaling up or scaling out your SQL Server setups.
I strongly urge you to read over the Waits and Queues whitepaper. It’ll take less than an hour. You’ll end up with a strong understanding of which parts of your hardware setup are working well, and which aren’t.

The Good: You don’t need to make code changes, risk big outages because of some fat-fingered LINQ statement, or have huge amounts of deployment risk. Modest hardware upgrades can be affordable.

The Bad: Eventually you need to start buying thousands of machines or really, really big servers. The cost of hardware, datacenter space, and HVAC will grow very quickly if you don’t do additional performance tuning.
The Ugly: That developer doing SELECT * FROM BIGTABLE (WITH HOLDLOCK, SERIALIZABLE, MAXDOP(1)) is still running his query after you upgrade.

No, that’s not the developer I meant
PermalinkDatabase Performance Is Like Cake: The Layer Model
23 March 2011

Do you have a performance problem with databases? I bet you do. Do you ever wonder about what to do next to fix it? I bet you have.
The best way to improve your database’s performance depends on your resources, your skills, and what you’ve done already. Also, the bigger the problem, the riskier the solution.
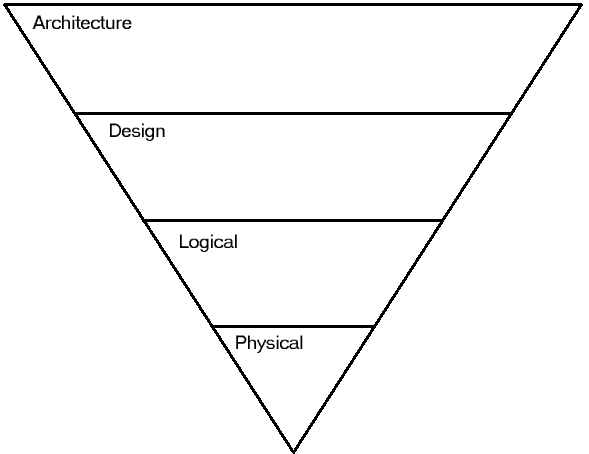
The Layer Model
I’ve come up with The Layer Model to do performance tuning. Systems have layers, or tiers, with different problems and solutions fitting into each layer. The risks and rewards are different in each layer. Most importantly, once you have optimized one layer, you should go up a layer to improve performance.

If you think about your system this way, you’ll have a reliable process to improve the performance of your applications.
Permalink