Popular Groceries using Data
09 January 2017
Everyone I know has trouble cooking. In my last blog post I looked at the most common ingredients in 24K recipes. I realized that there was a flaw in my previous post: it treated all recipes equally.
Recipes are not created equal. Some are more popular, for good reason. My recipe data set has information on recipe ratings, which are a good proximate metric for popularity. I used the ratings to compute a popularity ‘score’.
Data to the rescue, once again!

Common Ingredients
Of the ~103 million recipe-ingredient-rating combinations, half of them are in just 25 common ingredients. That’s a smaller number than the 50 ingredients needed in the previous post, probably because popular recipes use more similar ingredients than the average.
Let’s stick with the 50 most common ingredients for now, which cover 61% of 103 million recipe-ingredient-rating combinations.
This is great news for grocery shopping. We can make many popular recipes using the same number of ingredients.
Several common ingredients in the last post aren’t as popular this time around: nutmeg, pecans, potatoes, red bell peppers, thyme, and vinegar.
Conversely, several less common ingredients are more popular now: chili powder, lean beef, margarine, mozzarella cheese, paprika, and chocolate chips.
Pareto’s Pantry
I love the Pareto Principle, the “law of the vital few”. In this case, 79 ingredients out of 11K recipes cover 70% of the the recipe-ingredient-rating combinations in our data set. That’s only 0.68% of the ingredients in the list. A ‘vital few’, indeed.
Note: red means perishable, blue means nonperishable
This is the second of several posts on food and data, and there is more to come. Stay tuned!
PermalinkGroceries as a Data Problem
05 January 2017
The Benefits of Cooking
People spend a lot of money on healthcare, mostly on preventable diseases like Type-2 diabetes and heart disease. Poor diet is a key reason why. Restaurants, frozen meals, and fast food use ingredients that are worse for you than stuff you can cook yourself.
There are many structural reasons why it is hard to eat healthy (food deserts, healthy food is expensive, home cooking’s lower profit margin). It’s also psychologically harder to cook than to eat out.
I surveyed ~200 friends, and heard the same thing:
“I don’t know what to make for dinner”
After inquiring a bit more, I reframed the question:
“I don’t know what recipe(s) I could make with the ingredients in the house, or what groceries to keep stocked.”
Aha! It turns out one of the challenges to eating healthy is the psychological challenge of figuring out what to cook. That’s great, because it’s an information retrieval challenge. Data to the rescue!
A Data Problem
I have a recipe data set containing 24K recipes, each of which lists ingredients like chicken, tomatoes, or olive oil. There are ~11K unique ingredients and 216K recipe-ingredient combinations to look at.
I prefer to start simply, by counting.
Common Ingredients
Of the 216K recipe-ingredient combinations, half of them are just 50 common ingredients.
This is great news; I can keep a modest number of ingredients in stock and be able to make a huge variety of recipes. The frequency of ingredients follows a power law curve.
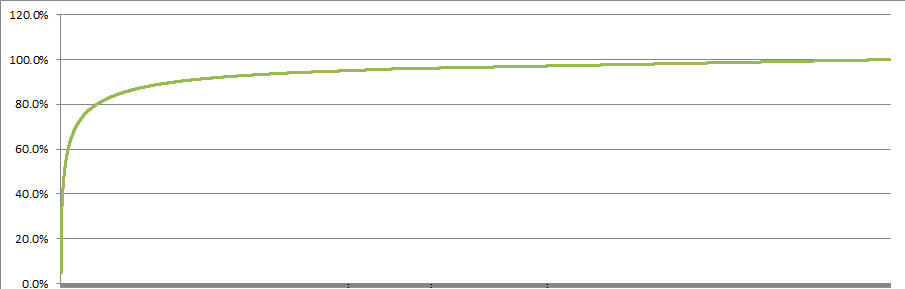{kind=link}
Unsurprisingly, the most frequent ingredients are salt, sugar, and pepper. There are also some I didn’t expect: cornstarch, pecans, mayonnaise.
Non-perishable Ingredients
Let’s look at non-perishable ingredients. These 60 items are 60% of the non-perishable ingredients in all recipes. ‘Non-perishable’ to mean it lasts at least a month in the fridge or pantry in my house.
These are the staples to keep handy, and to buy in bulk.
Perishable Ingredients
Let’s look at perishable ingredients next. These 21 ingredients are 60% of the perishable items in all recipes. That’s another small number of things to keep around, and many of these also last quite a while in a refrigerator.
I suspect that the most frequent ingredients are common because they are used in many cultures. Onions, garlic, tomatoes, and eggs are used around the world in a huge variety of dishes.
This is the start of several posts on food and data. Stay tuned!
Permalink