PASS Summit 2013 Keynote - Back to Basics
22 October 2013
Dr. David DeWitt recently presented a keynote (video, slides) for PASS Summit 2013 on the new Hekaton query engine. I was impressed by how the new engine design is rooted in basic engineering principles.
First Principles
Software engineers and IT staff are bound to the economics and practicalities of the computing industry. These trends define what we can reasonably do.
1: It’s About Latency
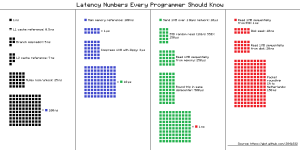
Peter Norvig, Director of Research at Google, famously wrote Numbers Every Programmer Should Know, describing the latency of different operations.
When a CPU is doing work, the job of the rest of the computer is to feed it data and instructions. Reading 1MB of data from memory is ~ 800 times faster than reading it sequentially from a disk.
A recent hype has been “in-memory” technology. These products are based on a constraint: RAM is far, far faster than the disk or network.
“In-memory” means “stored in RAM”. It’s hard to market “stored in RAM” as the new hotness when it’s been around for decades.
2: It’s About Money
The price of CPU cycles has dropped dramatically. So has the cost of basic storage and RAM.
You can buy a 10-core server with 1 terabyte of RAM for $50K. That’s cheaper than hiring a single developer or DBA. It is now cost effective to fit database workloads entirely into memory.
3: It’s About Humility
I can write code that is infinitely fast, has 0 bugs, and is infinitely scalable. How? By removing it.
The best way to make something faster is to have it do less work.
4: It’s About Physics
CPU scaling is running out of headroom. Even if Moore’s Law isn’t ending, it has transformed into something less useful. Single-threaded performance hasn’t improved in some time. The current trend is to add cores.
What software and hardware companies have done is add support for parallel and multicore programming. Unfortunately, parallel programming is notoriously difficult, and runs head-first into a painful problem:

Amdahl’s Law
As the amount of parallel code increases, the serial part of the code becomes the bottleneck.
Luckily for us, truly brilliant people, like Dr. Maurice Herlihy, have invented entirely parallel architectures.
5: It’s About Quality Data
“Big Data” is all the rage nowadays. The number and quality of sensors has increased dramatically, and people are putting more of their information online. A few places have truly big data, like Facebook, Google or the NSA.
For most companies, however, the volume of quality data isn’t increasing at nearly as rapid a pace. I see this all the time; OLTP databases are growing at a much smaller pace than their associated ‘big data’ click-streams.
6: It’s About Risk
Systems are not upgraded quickly. IT professionals live with a hard truth: change brings risk. For existing systems the benefit of change must outweigh the cost.
Many NoSQL deployments are in new companies or architectures because they don’t have to migrate and re-architect an existing (and presumably working) system.
Backwards compatibility is a huge selling point. It reduces risk.
7: It’s About Overhead
Brilliant ideas don’t come from large groups. The most impressive changes come from small groups of dedicated people.

However, most companies have overhead (email, managers, PMs, accounting, etc). It is easy to destroy a team’s productivity by adding overhead.
I have been in teams where 3 weeks of design/coding/testing work required 4 **months **of planning and project approvals.
Overhead drains productive time _and _morale.
Smart companies realize this and build isolated labs:
- AT&T had Bell Labs
- Microsoft has MS Research
- Lockheed had Skunk Works
- Obama for America had its Technology team
- Facebook had its Battle Cave
The Keynote
Dr. DeWitt’s keynote covered how these basic principles contributed to the Hekaton project.
- Be Faster, Cheaper: Assume the workload is entirely in memory because RAM is cheap. Optimize data structures for random access
- Do Less Work: Reduce instructions-per-transaction using compiled procedures
- Avoid Amdahl’s Law: Avoid locks and latches using MVCC and a latch-free design. The only shared objects I could identify were the clock generator and the transaction log.
- Sell to Real People: Build it into SQL Server with backwards compatibility to encourage adoption.
- Build It Smartly: Use a small team of dedicated professionals. The Jim Gray Systems Lab has 9 staff and 7 grad students. Microsoft’s Hekaton team had 7 people. That’s it.
…Gotcha!
I have hope for the new query engine, but also concerns:
- It’s only in SQL Server Enterprise Edition (\(\)). Microsoft’s business folks clearly aren’t encouraging wide adoption of this feature.
- The list of restrictions for compiled stored procedures makes them useless without major code changes
- The new cost model and query optimizer will have bugs. It took years of revisions for the existing optimizer to stabilize.
Here Endeth the Lesson:
- Make architecture changes based on sound engineering principles**
- Assemble a small group of brilliant people, and then get out of the way.**