Improving Database Performance: The Layer Model

Do you have a performance problem with databases? I bet you do. Do you ever wonder about what to do next to fix it? I bet you have.
The best way to improve your database’s performance depends on your resources, your skills, and what you’ve done already. The bigger the problem, the riskier the solution.
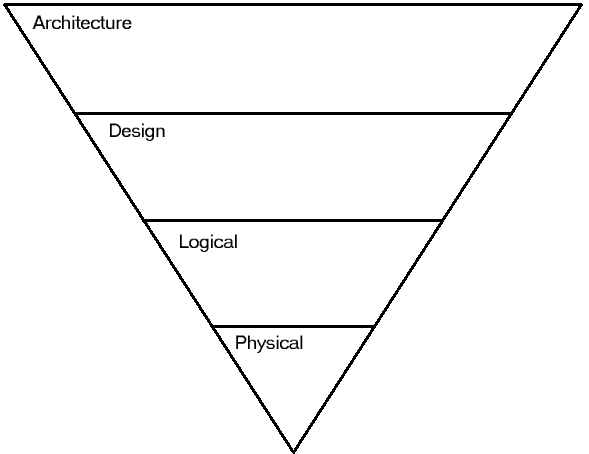
The Layer Model
I’ve come up with The Layer Model to do performance tuning. Systems have layers, or tiers, with different problems and solutions fitting into each layer. The risks and rewards are different in each layer. Most importantly, once you have optimized one layer, you should go up a layer to improve performance.

If you think about your system this way, you’ll have a reliable process to improve the performance of your applications.
“Build It, and Perf Will Come”

Layer 1 of The Layer Model is the physical layer.
The physical layer is the hardware used to make your database run. If you add more/better hardware, you can get better performance. Just add a faster SAN array, more RAM, more CPU cores, etc. Hardware upgrades will improve your application’s performance. Of course, you need to know which hardware to add.
The best way to do this is to use the Waits and Queues method. It quickly identifies the bottlenecks in your system, so you can tune hardware in the places you need it most.

The main Waits and Queues whitepaper is here, written by Tom Davidson. In addition, I’ve found a few blog posts to be very helpful. Paul Randal (b / t) has a great post expanding on the different wait types, with some example queries to get you started. The other fantastic resource is Brent Ozar’s (b / t) series of blog posts on scaling up or scaling out your SQL Server setups.
I strongly urge you to read over the Waits and Queues whitepaper. It’ll take less than an hour. You’ll end up with a strong understanding of which parts of your hardware setup are working well, and which aren’t.

The Good: You don’t need to make code changes, risk big outages because of some fat-fingered LINQ statement, or have huge amounts of deployment risk. Modest hardware upgrades can be affordable.

The Bad: Eventually you need to start buying thousands of machines or really, really big servers. The cost of hardware, datacenter space, and HVAC will grow very quickly if you don’t do additional performance tuning.
The Ugly: That developer doing SELECT * FROM BIGTABLE (WITH HOLDLOCK, SERIALIZABLE, MAXDOP(1)) is still running his query after you upgrade.

No, that’s not the developer I meant
“Tune it, and perf will come”
Layer 2 of The Layer Model is the logical layer.
You could also use the OPTION (LUDICROUS SPEED) query hint

The logical layer represents the configuration of your indexes, statistics, and the queries that are run on your system. If you tune your indexes and your worst queries, you will get better performance. The best way I know of to do this is to use DMVs and logging.
Before we start, however, it’s important to remember that you’ll never run out of ways to tune performance. It is important to have goals before doing performance tuning. Know when to stop and declare victory. The 80/20 rule works really well here.
Index Tuning

How do you do index tuning? You ESCape! Eliminate. Swap. Create.
- Eliminate. Eliminate indexes that are never used. All they do is suck up space and slow down your database’s insert/update/delete/merge operations.
- Swap. Are the remaining indexes the best configuration for what you have? Probably not. Changing their included column configuration, index column order, or adding an additional column could give you better performance without much extra overhead.
- Create. Create new indexes that are needed. This should only be done a while after you’ve swapped indexes around. Then it’s time to go looking in the index DMVs again to figure out what additional indexes might be useful.
There have been many, many blog posts on index tuning. My favorites are below. These links also have pointers to a lot of additional content. Brent Ozar’s video on index tuning SQLServerPedia’s best practices on creating tuning. Kimberly Tripp’s posts on spring cleaning for your indexes. SQLServerPedia’s list of index-related DMV queries.
Query Tuning
Query tuning can tricky. I have found that having the right data before you start makes everything easier. So, first, collect all of the query information you can get. Get lists of queries that have run, with details on CPU time, execution counts, and missing indexes or missing stats mentioned in the query plan. The sys.dm_exec_query_stats DMV is great for this.
From there, I would suggest you:
- Identify long-running queries
- Identify queries that run constantly
- Identify blocking/deadlocking queries
- Document everything. Excel is handy for this sort of thing.
Now you have a big list of queries, along with details of their usage. The next step is to prioritize what to work on. I like to prioritize query optimization based on user pain, error counts, and then system stability.
- User Pain. If a user is complaining about a particularly slow sproc or query, I’ll see if it can be optimized. If nothing else, doing this gives me some breathing room to work on other issues. It also makes my IT organization look responsive, which is always a plus.
- Error counts. If you have a query that is causing lots of deadlocks or blocking, work on it next. It’s probably creating cascading performance problems throughout your system.
- System stability. Look at the rest of your queries. Rank them by CPU time and I/O usage, starting with the worst offenders. Tune those first. Tuning a modest number of queries often results in dramatic performance gains for the entire system.
Summary

The Good: It’s easy to find & eliminate bottlenecks one by one, using fairly simple query tuning tricks and the DMVs built into SQL Server.

The Bad: Logical-layer tuning requires modest development time, and it can be a little risky. Changing indexes can slow your system down further. Query tuning can return incorrect results to users, or slow down the queries even more.

The Ugly: That web application that runs 10 million SELECT queries per minute against your database? It’s still there. That reporting sproc that does a 25-way join with GROUP BY? It can only be tuned so much. And no amount of tuning will make that 50TB database run fast on your Pentium Pro-based server with 2GB of RAM.
“Refactor it, and perf will come”
Layer 3 of The Layer Model is the design layer. The design layer is the schema of your tables and the application interfaces into your database. Each table’s datatypes, the views and stored procedures used by applications, LINQ, Entity Framework…they are the design layer of your database. Clean up your design, and you will get better performance.
Work with your developers

To do any of this work, there must be a good working relationship between the DBA team and the development team(s). Everybody needs to get along. These tuning techniques require DBAs, database developers, and C# developers to work well together. All of us will be working outside of our comfort zone.
Data-Access Tuning
The way that applications access your database has a lot of influence on how well your application behaves, and the load on your database. Does your UI or middle-tier use LINQ everywhere? Is it all done through stored procedures? Some other way?
Luckily, developers are pretty conservative (read: lazy), so your application probably only uses one set of tools to access the databases.
{kind=link}
Stored Procedures
If your application always calls stored procedures (‘sprocs’), then you’re in luck. There are a lot of things you can do for performance tuning on your own. I’d recommend the following approach:
1. Do query tuning for the stored procedures in your system. 2. Do you have multiple applications hitting the same database? Consider making different stored procedures for each one. That way you can tune each application independently, and not have to worry about the others. That way a set of stored procedures becomes the application<->database interface layer. 3. Make sure each stored procedure is doing the minimum amount of work necessary. If you only need to return 2 columns to your application, only return those 2, instead of all 20 in the table.
Object to Relational Mappers

If your application uses an Object-to-Relational Mapper (ORM) like LINQ, Entity Framework, or nHibernate, then brace yourself. ORM tools hide a lot of query information from DBAs. They don’t expose information on what queries they create, and those queries are often hard to tune because nobody can re-write them directly. They make it hard for anyone to understand what the application is doing with your database.
For this post, I’m going to stick with tuning LINQ to SQL, since it seems to be the most common ORM tool with my readers. Nowadays I can’t swing a stick without hitting someone who’s run into performance issues using LINQ to SQL. Some intrepid souls have even benchmarked the performance hit you might receive, and the results may make you want to cry.

Luckily, this problem is common enough that there are a lot of resources around how to go performance tuning. Some of my favorites are below.
- Sidar Ok’s (b)10 Tips to Improve your LINQ to SQL application performance.
- Scott Guthrie’s post on the LINQ to SQL debug visualizer
- Rico Mariani’s series on performance tuning LINQ to SQL
- Mark Friedman’s post on the Tier Interaction Profiler
All of these resources require that DBAs and developers work together. They often require that developers have access to a database that’s similar in size to your production system, to find out what’s going on. However, it’s a great way to speed up your systems and meet nerdy colleagues.
Table Tuning
Table tuning isn’t talked about very often. Why would you change the schema of a table for performance? Isn’t it usually done only for new features, or to add data integrity?
The reason is that your table schema can _dramatically _change how your queries behave. Consider these two examples, which can be used for the exact same application:
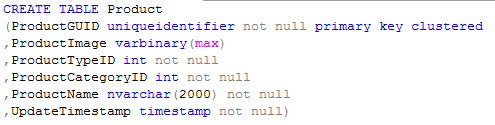
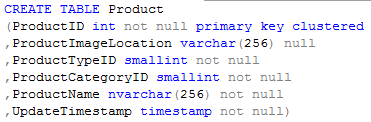
Let’s say the table had 1 million rows. The first table would need 197MB for the clustered index. It also needs an additional 2GB for the images being stored as LOBs. The second table would need 107MB for the clustered index, and nothing else. That’s a space savings of over 95%.
I’d recommend the following approach:
- Make sure it’s safe to redesign your tables. That means making sure stored procedures are used everywhere, or views, or you have agreement from the folks working with the ORM tools you have.
- Redesign the largest tables first.
- Resign the tables that have the worst blocking or deadlocks.
- Redesign ‘core’ tables. If a table is involved in over ~20% of your application’s queries, it’s a ‘core’ table
- Redesign anything else.

There are some great resources on table design. My favorite starting point, however, is Kimberly Tripp’s blog post on GUIDs.
Summary

The Good: Great performance improvements are possible (5x-100x is very achievable). Space savings come along as well.

The Bad: Development teams can be busy and tiring. There is a medium amount of development risk. If you don’t have a good database developer, you could make things worse, and break your applications in the process.

The Ugly: That application that is using LINQ to SQL on 1000 active spids against your lone OLTP database? It’s still there, even if the queries finish faster.
“Re-think it, and perf will come”
Layer 4 of The Layer Model is the architecture layer.
The architecture layer represents the high-level system design of your application, the technologies used, and how various systems interact with each other. If you change your architecture to be a better fit for your application, you will get far better performance. If you’re considering architecture work, that means you have tried all of the other, easier approaches to performance tuning. That means you have tuned your system’s hardware bottlenecks, tuned the indexes and queries being run, you have even tuned your table designs and data-access layer. What is left is an architectural solution.

How to Start
When people hear ‘architecture’, they often feel intimidated. Working with the entire system is daunting. Luckily, there’s a process that makes this easy. The key to architecture work is about choosing the right tools and design for the situation. Here’s a 4-step guide:
- What is the essence of the problem?
- What high-level designs do other people use for the same problem?
- Which design, after minor adjustments, is the best fit for your situation?
- What tools should you use for your modified system architecture?

The essence of the problem
Architectural challenges have a root problem. This is the essential issue, that, if fixed, makes all of the other problems much smaller. Since we are IT professionals, identifying root cause is something we’re good at.
What is the root problem with your system? Do you have single 80TB database powering your entire reporting system? A single OLTP system growing by 10X every month? Are there 80 critical system components that each need to talk to all of the others?
Knowing the problem is half the battle.
What other architectures do people use?

Brilliant innovators are very rare
Some of us can produce brilliant, never-before-seen system architectures that work. They’re rare. For the rest of us, we mimic the designs and best practices we hear about. Doing this is very wise; you can learn the strengths and weaknesses of many system designs without trying them out.
Luckily for us, the SQL Server community is very active. Chances are you have access to a nearby SQL Saturday, lots of helpful professionals on Twitter, and a gaggle of blogs with great resources. Most importantly, all of the people I’ve met in the community are easy to talk to.
I can learn more about architecture in an evening than in 6 months of reading. How? I offer to buy a 6 smart, experienced engineers a round of drinks after an event, and ask them lots of questions. Or I will find the one subject matter expert in this area, and expense a fancy dinner. Your manager should happily pay a $200 bill to avoid 6 months of project headaches.
Find out what others have done, and you benefit from decades of experience at a very low price.
CHOOSING THE RIGHT DESIGN
The scales of IT are not blind

Now you know the core problem to solve, and what others have done that works.
You should pick a system architecture based on what you know. I do this in a 5-step process:
- What are the 2-3 most critical requirements for my system, and my business? Scale? Latency? Interoperability? Ease of adding new features?
- Which architectures _do not do well _with these requirements? Discard the ones that don’t fit.
- Of the remaining ideas, list the strengths and weaknesses of each.
- Pick one.
- Tweak the system design a bit, but only to address your critical requirements.
Choose the right design, using good judgment and a critical eye.
Using the right tools

Some stacks are more fragile than others
You now have a proposed system architecture. Now you need tools. The last step is to pick a technology stack for the job. I’ve saved this step for last because the choice of system architecture should dictate which technologies you use, and not the other way around. I like to do the following:
- List the top 3 most common technologies for the problem. Is it SQL Server? WCF? Memcached? Windows Azure AppFabric?
- List the strengths and weaknesses of each. If you are familiar with a technology stack, that is a key strength.
- Pick one.
Pick the right tools for your design, and you’ll have an architecture that can last for years.
The Good:

Re-architecting a system can give you a faster, more scalable, and easier to use system for years. It can reduce dozens of headaches for users and IT in one fell swoop. It can also foster a sense of camaraderie between IT, developers, program managers, and the business. After all, you’re all in this together.
The Bad:

This is high-risk work. Doing this without testing is a recipe for horror. Bad communications and planning dooms a project this size. A lot depends on the judgment and teamwork of a few key IT and development personnel.
The Ugly:
Done wrong, you can completely screw up your system architecture, alienate various teams from each other, and lose massive amounts of money as your customers flee.

But wait, there’s more!
Several people have asked me for examples of architecture re-work, design tuning, and so forth. I’ll be putting together several posts over the next few weeks with examples, best practices, and anti patterns.
Published 23 March 2011