T-SQL Tuesday #25 - Tips and Tricks
13 December 2011

It is T-SQL Tuesday once again, hosted by Allen White (b / t). The theme for this T-SQL Tuesday is Tricks.
One of my favorite tricks is to use INTERSECT when I have to rewrite a SELECT query, to make sure I am returning the same data.
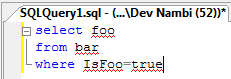
Let’s say I have a slow query that returns 1640 rows:
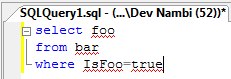
I refactor it for speed, and make sure it still returns 1640 rows:
How am I sure my new query returns the same data? I use INTERSECT, and make sure the intersect-ed query returns the same number of rows as the original query:
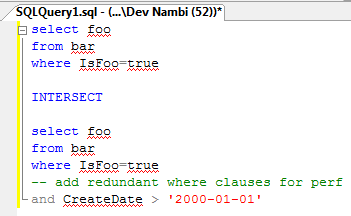

“Success is concrete. Just like the Mafia.”
Now I know my changes have not affected what data is returned. Success!
I also have a more concrete example, using the AdventureWorks2008 R2 database, and Example.sql .
PermalinkMeme Tuesday - Improvements to SQL Server
06 December 2011
 |
|
|---|---|
| Why So Serious? |
Yesterday’s funny post was about Meme Monday.
Today’s post is the sequel: Meme Tuesday. This is a more serious post.
Here’s a list of features and changes I wish Microsoft would make:
- Dynamic query re-optimization. If a query is doing badly, have the SQL engine detect that and re-optimized it on the fly for better performance.
- Give the MVPs even more influence over which SQL Server products are developed.
- Give DBAs the ability to create filegroups in tempdb, and assign different tempdb usages to each. I’d love to have user temp tables, sorts, hashes, RCSI data, and rollback data be separated, so I can tune them separately.
- Make Enterprise features available in Standard edition. Table compression and backup compression are at the top of my list.
- Object-level and index-level backups and restores. I would love to choose which of my nonclustered indexes to back up, because I don’t need most of them in emergencies.
- Let companies build their own PDW instances. Very few companies can afford the multi-million dollar price tag attached to a PDW appliance. They’ll usually pay somebody to change the code rather than
- Add built-in support for code libraries.
- Change your SQL Server 2012 licensing scheme to be roughly on par with the old prices. The current increase in prices is going to encourage adoption of NoSQL and open-source alternatives.